 |
It's easy to see how this architecture resembles the stream computing model described in the previous section. This type of fixed architecture was, until very recently, the standard for computer graphic card manufacturers to follow. Although it resembled a stream computing model, it offered little or no programmability to users thus, it was not usable for any task other than processing graphic instructions. In 2000 [Owe05], GPUS allowed some level of programmability of key parts of the pipeline.
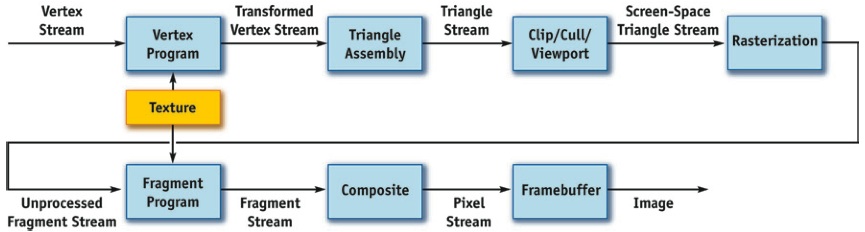
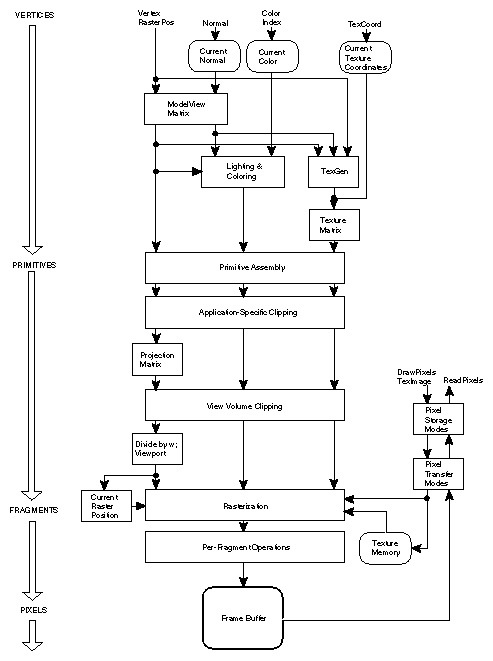
Current GPUS allow the user to program almost any type of functionality at two stages of the graphic pipeline in the form of vertex programs and fragment programs. These allow the user to write programs on vertex and fragment data respectively. The figure 2 shows a mapping of the more recent OpenGL programmable pipeline to a stream model.
The vertex processor operates on incoming vertex values and their associated data. It is intended to perform traditional graphics operations such as: vertex transformation, normal transformation and normalisation, texture coordinate generation and transformation, lighting and colour calculations [Ros04]. Because vertex processor are capable of changing the position of incoming vertex data, thus affecting the final image to be drawn. Since an image is, in essence, an array of memory, vertex processor are capable of scatter-like operations. Also, recent processors are capable of reading from texture memory, resulting in a special kind of delayed-gathering operation. We call it delayed because the vertex cannot read information directly from another vertex element but it can read whatever data resulted from a previous computation if it is encoded in texture memory. In later sections, we will see how to take advantage of this to perform simple computation.
Vertex processors can operate in SIMD(Single Instruction, Multiple Data) or MIMD(Multiple Instruction, Multiple Data) modes; thus, allowing both, instruction and task parallelism within a single processor unit. Since modern GPUS contain multiple vertex processors (latest NVIDIA and ATI cards have up to six) we can begin to appreciate the level of parallelism achievable on these architectures.
The fragment processor operates on fragments and their associated data. Some of the operations traditionally associated with fragment shaders are: texture access and application, fog, colour sum and general operations on interpolated values. As with vertex shaders, fragment shaders can be used to perform almost any kind of computation on the GPU. Because of the fragment processor can access texture memory randomly it is very easy to perform gathering operations within a fragment program. In fact, it is not uncommon to use a texture information to dependency look-ups on other textures; feature that comes really handy when porting algorithms to the stream computing model.
Although fragment processor in current GPU architectures can only operate in SIMD mode and are very restrictive about the kind of operations they allow we shall see that they are still very apt to perform general computations. Plus, due the computational frequency of fragment processing the number of fragment processors is higher than the number of vertex processors. Current top-of-the-line cards have about sixteen fragment processors.